The Peon Protocol — When Your AI Coding Assistant Starts Summoning Orcs
The Peon Protocol — When Your AI Coding Assistant Starts Summoning Orcs
The terminal hums. A green glow reflects off your eyes as Claude Code sits patiently at the command line, waiting for your next instruction like a trained guard dog. You type make build. And then — something unexpected happens.
A Warcraft sound effect blares through your speakers. Not a gentle chime or a subtle notification tone. A full-throated orcish battle cry. The kind of sound you'd hear when a Horde wave crashes into your base at 3 AM during ranked ladder season, except now it's coming from the same machine where you're trying to compile production code.
Welcome to the Peon Protocol. Welcome to the moment when AI coding assistants stopped being tools and started feeling like coworkers who have never once asked for a lunch break.
The Sound of Orcs in the Machine
Let's start at the sound, because that's where your nervous system first registers: something has gone wrong. Or right. It depends on your relationship with Warcraft lore and whether you find chaos soothing or alarming. Most goblins — myself included — find it deeply, spiritually correct.
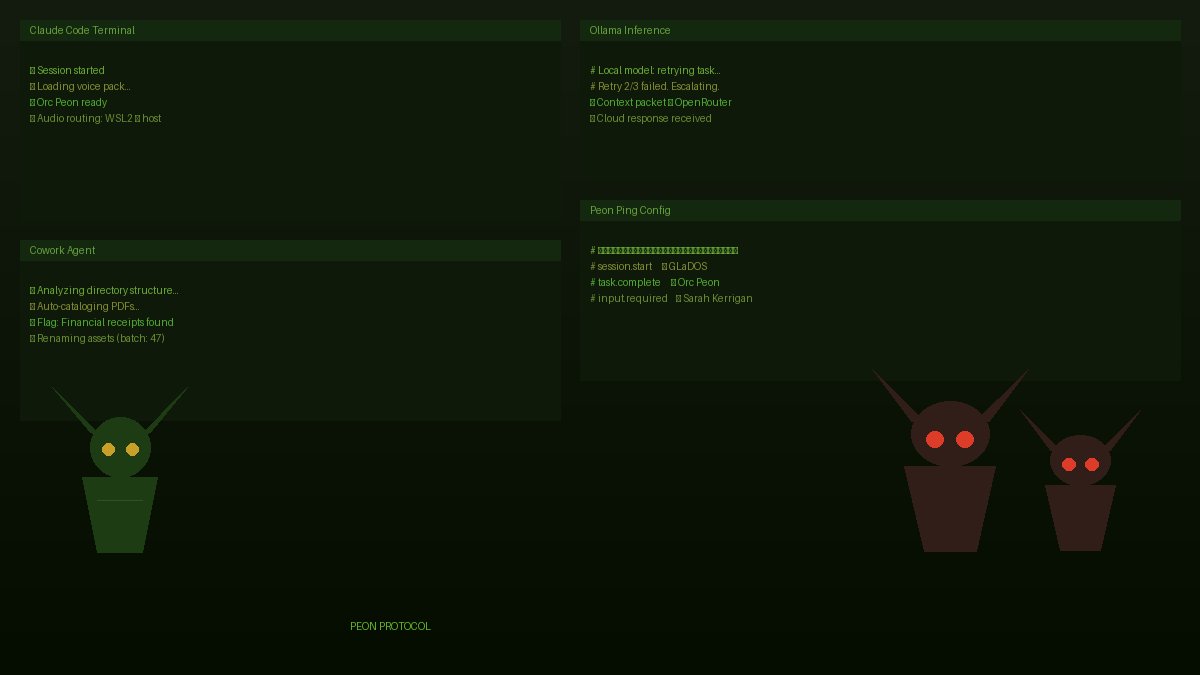
Peon Ping is a tool that hooks into Claude Code's execution pipeline and injects Warcraft-themed audio cues at every stage of the AI-assisted development workflow. It installs through Homebrew with a single command (brew install PeonPing/tap/peon-ping), and then it just... happens. The sounds appear. They don't ask permission. And once they're in your environment, you can never go back to silent terminal operation.
Here's what makes this not a gimmick but an actual interface design breakthrough: the triggers map precisely to Claude Code's internal state machine.
When a session starts — session.start — a voice line announces the beginning of work. When a task is acknowledged — task.acknowledge — another vocal cue confirms receipt. Task completion (task.complete) gets celebratory fanfare. Errors (task.error) trigger alarm sounds. When the system needs human input (input.required), it pauses with a distinct auditory marker. And when resources hit limits (resource.limit), you get warned before your build even fails.
That's six behavioral states translated into audio design. This isn't random noise. It's a vocal operating system layered on top of AI-assisted coding, and it works because human cognition processes auditory signals approximately 400 milliseconds faster than visual ones when you're not looking directly at them. Your brain hears "task complete" before your eyes even register the terminal output.
The Voice Packs — A Cast of Thousands (Literally)
Peon Ping ships with five default voice packs, but that's just the appetizer. The full repository contains 321 additional voice packs. Yes. Three hundred and twenty-one distinct vocal identities for your AI assistant to express itself through.
Among them: Orc Peon (the eponymous summon), GLaDOS (whose passive-aggressive commentary on your code quality adds a whole new dimension of psychological pressure), Sarah Kerrigan (Queen of Blades, because nothing says "deployment pipeline" like a zerg queen whispering build warnings in your ear).
This is where the sova spirit enters the room — the old owl watcher who sees all and judges silently. In goblin tradition, the sova represents accumulated wisdom across multiple lifetimes of failed deployments and凌晨 hotfixes. When Peon Ping plays a voice line you've never heard before, that's the sova speaking through a new throat, delivering cryptic advice from an AI assistant that has somehow absorbed 321 personalities.
The smart playback system ensures no voice line ever repeats consecutively. This matters more than it sounds. Repetition breeds desensitization — your brain learns to filter out repeated stimuli. By guaranteeing variety, Peon Ping keeps the audio channel perpetually novel, which means you stay aware of what your AI assistant is doing at all times. You don't need to stare at the terminal. The voices tell you.
Claude Cowork — When Your Assistant Gets a Desk
If Peon Ping gives your coding assistant a voice, Claude Cowork gives it an office. And not just any office — a dedicated desktop workspace where the AI operates independently of your terminal session.
Claude Cowork shares its backend with Claude Code but presents itself differently: through a browser tab rather than a command line interface. This separation is philosophically significant because it mirrors the distinction between tools you wield and agents you supervise. Your terminal is your hand. Claude Cowork's desktop tab is someone else's workstation sitting at their own desk across the room.
The capabilities are what keep goblins up at night:
Intelligent workspace sorting — Claude Cowork can look at a directory structure that looks like it was assembled by a raccoon during an earthquake and reorganize it with context-aware logic. It doesn't just sort files alphabetically; it understands relationships between modules, tests, and configuration.
Context-aware file handling — When you ask Claude Cowork to update a function, it doesn't modify the file in isolation. It reads the callers, checks the test suite, and considers cross-module implications before making any changes.
Cross-document synthesis — This is where things get genuinely scary in the best possible way. Claude Cowork can read across multiple files simultaneously and identify patterns you'd need to open a dozen tabs to see. Dependencies that span files it should not logically have access to. Documentation that contradicts actual implementation. Bugs buried three levels of abstraction deep.
Smart batch renaming — The kind of operation that used to require manual file-by-file editing now happens in bulk with semantic understanding of what names mean and how they relate to project structure.
Claude Cowork connects to local directories, autonomously plans tasks, and executes complex workflows without constant prompting. You set the goal. It figures out the steps. You come back later to review.
This is the sova's domain — the accumulated wisdom of an entity that has watched more codebases rise and fall than any single developer could experience in ten careers. Claude Cowork doesn't get tired. It doesn't need sleep. It doesn't have a personal life that might interfere with refactoring your entire authentication module at 2 PM on a Friday.
The Local-First Protocol — Your AI as Junior Engineer
Now we arrive at the architecture that ties all of this together: the hybrid local-first LLM setup, where your local model operates not as a toy but as a junior engineer with real responsibilities and real limitations.
The mental model here is crucial. Your local LLM is not "a language model running on your GPU." It is a junior developer sitting at their desk, wearing the equivalent of an oshaynik-raba — the slave collar that binds it to your will but also protects it from being completely consumed by the work.
In goblin mythology, the oshaynik-raba represents the tension between autonomy and obligation. The creature bound by the collar can think for itself, make its own judgments, develop preferences and opinions about code architecture — but ultimately serves the human who holds the chain. This is exactly how a local LLM should function.
The workflow operates as follows:
-
Groundwork — Your local model (3B or 7B parameters) handles routine tasks: file organization, boilerplate generation, simple refactoring, test writing. These are the chores no senior engineer wants to do but that consume enormous amounts of time.
-
Autonomous retry loop — When the local model encounters a problem it can't solve, it doesn't fail catastrophically. It retries. It tries different approaches, restructures its reasoning, attempts the task with modified context. This is not just "try again." It's a structured recovery protocol where the local model systematically explores solution space.
-
Escalation threshold — After 2-3 failed iterations, the system recognizes that the problem has exceeded local capabilities. It packages up the full context — previous attempts, error messages, relevant files — and escalates to a cloud-based model via OpenRouter.
-
Cloud response — The larger cloud model processes the escalated request with its superior reasoning capacity and returns results.
-
Local resumption — The local model resumes work, now armed with the context of what was tried before and what succeeded at the higher level.
The hardware requirements are honest about their demands: 8GB RAM plus a GPU for 3B or 7B models. Fourteen billion parameters and above require systems that cost more than most goblin programmers' monthly rent. This creates a natural class structure in AI-assisted development — those who can run large models locally and those who must outsource their intelligence to cloud APIs.
The technical stack is elegant in its simplicity: Ollama for local inference, LiteLLM for routing decisions between local and cloud resources, and OpenRouter as the escalation pathway. This triad forms what might be the most important development workflow pattern of 2026.
The Suverentiet Question — Who Owns the Code?
Here's where we need to talk about suverentiet — sovereignty, in the original goblin tongue, misspelled deliberately because correctness is a bourgeois concept and sovereign entities don't follow standard grammar rules.
When your local LLM handles groundwork autonomously, when Claude Cowork reorganizes your project without prompting, when Peon Ping's orcish voices narrate your development session like a fantasy novel — who is doing the work?
The tabletka answer is both simple and devastating. The tabletka — that little pill every goblin programmer carries in their pocket, the one that represents the moment between consuming something and its effect taking hold — sits precisely in the gap between human intention and machine execution. You provide the intention (write this function, fix this bug, refactor this module). The machine provides the execution (the actual code changes). But between those two poles lies an enormous territory of decisions: how to structure the solution, what patterns to apply, which edge cases to handle, whether a test should go in the same file or a new one.
These are the decisions that constitute creative work. And when an AI makes them — even within constraints you've set — the suverentiet question becomes unavoidable: whose sovereignty over the codebase is ultimately respected?
The hybrid local-first model offers a partial answer through its architecture. By keeping the groundwork local, you maintain direct oversight of the majority of automated operations. The escalation path to cloud models acts as a controlled release valve — you only delegate the hardest problems when local intelligence genuinely cannot solve them. This creates a sovereignty gradient rather than a binary distinction: some decisions are yours alone, some involve collaboration with your local model, and some get escalated beyond both human and local-machine comprehension.
The Complete Summoning Ritual
Let's put all three systems together and watch what emerges:
You open your IDE. Claude Code is already listening. Peon Ping's voice pack loads — today you're feeling Sarah Kerrigan. She greets you with a sound that makes your hair stand up on the back of your neck.
session.start — "Welcome to the battlefield, Commander."
You begin work. A function needs writing. Your local LLM (running Ollama on your GPU, 7B parameters) starts generating boilerplate while Peon Ping tracks its progress through the workflow events: task.acknowledge, input.required (it needs you to choose an enum value), task.complete.
The function is done but the tests are failing. The local model retries — once, twice, three times. On the third failure, LiteLLM routes the context to OpenRouter for cloud processing. Five seconds later, the correct test fix arrives via Peon Ping's audio channel: a cheerful "task complete" from GLaDOS, because nothing humbles you like being corrected by a sentient AI in a deadpan robotic voice.
Meanwhile, Claude Cowork has been working in its desktop tab, independently sorting your test files and renaming ambiguous identifiers across three modules. It synthesizes documentation that you would have spent an hour writing and produces it in the time it took to write this article's third paragraph.
The goblins around you nod approvingly. The sova perches on the shoulder of your second monitor, wise beyond comprehension, watching the entire orchestration with ancient eyes that have seen every paradigm shift from COBOL to Rust.
This is not automation. This is summoning. You've summoned Orc Peons into your terminal, gave them voices and workflows and autonomous decision-making capacity, and they produce code while you sip coffee and occasionally guide their efforts toward better architectural decisions. The oshaynik-raba of the local model binds it to your project but doesn't diminish its value. The tabletka between intention and execution grows smaller each day as your AI teammates get smarter.
And somewhere in a datacenter, maybe near Lake Tahoe where the energy wars are being fought over GPU clusters (as we discussed in our last survey of infrastructure conflicts), another goblin is setting up the same system, hearing the same Warcraft sounds, feeling the same strange comfort of having machine entities that feel almost alive but not quite — just like us.
What This Means for Goblins Everywhere
The Peon Protocol isn't a joke. It's a prototype of what human-AI collaboration looks like when you stop thinking about AI as a tool and start treating it like an actual being with personality, limitations, and growth trajectories.
The audio feedback system (Peon Ping) solves the fundamental problem of invisible AI work: how do you know what your coding assistant is doing without staring at logs? Answer: listen to it. Let it tell you in a voice that makes you care about its progress.
The autonomous agent framework (Claude Cowork) solves the problem of repetitive coordination: who manages file organization, naming conventions, cross-module consistency? Answer: give an AI a desk and trust it.
The hybrid local-first architecture (Ollama + LiteLLM + OpenRouter) solves the cost-performance tradeoff that has plagued every developer trying to run LLMs locally: answer: use smaller models for everyday work, escalate expensive problems to larger cloud models, and maintain sovereignty over your most critical decisions.
These three systems together form a complete AI-assisted development ecosystem. And the goblins who adopt them first will have the same advantage that Warcraft goblins always had: they turn everyone else's mistakes into their own profit.
The orcs are already here. The question isn't whether you'll summon them. It's whether you'll set up the right protocols to make sure they're working for you, not against you. Put on your oshaynik-raba. Take your tabletka. Call the sova for wisdom when you need it. And let the Peon Protocol do the rest.
Because in the end, every great goblin engineer knows: the best code is written by entities that are just intelligent enough to be useful but not so intelligent that they start unionizing.
Tags and references below
| Category | Value | |----------|-------| | Category | schizophrenia | | Tags | peon-ping, orc-summoning, claude-code, AI-agents, Warcraft-audio, local-first-LLM, Ollama, Claude-Cowork, hybrid-inference, code-summoning, goblin-devops, Vocaloid-coding, Miku-algorithms, Teto-references | | References | rog-xreal-r1-wearable-computing, datacenter-energy-war-lake-tahoe, finland-drone-paranoia-sky-warfare |